Project outcomes: Using the models
How to use the trained pxtextmining models
For any technical support, or to get the URLs for the APIs, please contact the project team. Technical documentation, including code examples, is available on the pxtextmining technical documentation page.
Option A: Using the APIs
We have set up two different APIs for the models. API stands for Application Programming Interface. They allow you to use the machine learning models to make predictions on your text, without having to run them yourself. You send your data to the API via a secure HTTPS connection over the internet.
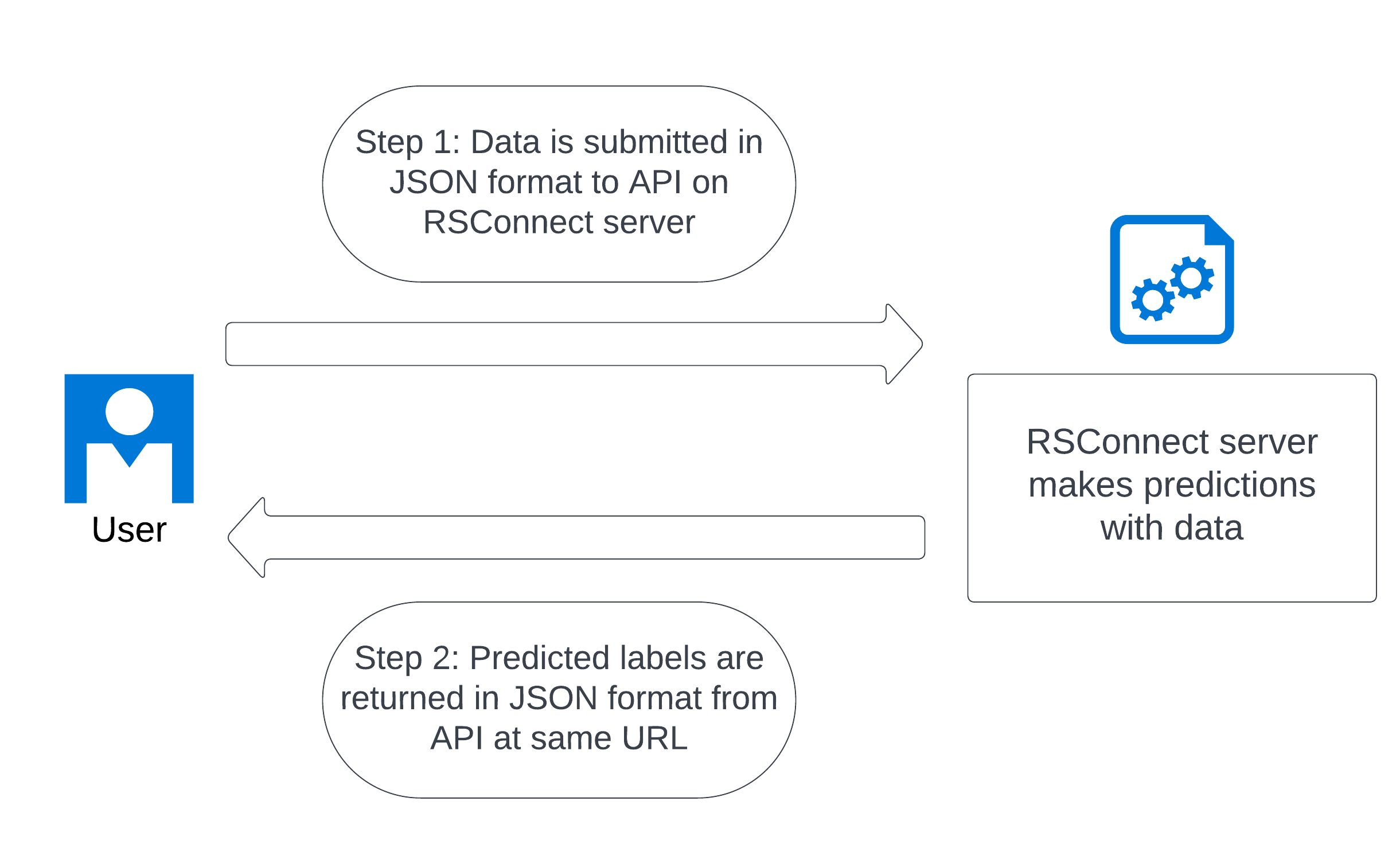
The Quick API (Less accurate model, very fast)
This API is fast and easy to use, but only utilises one of the four models that make up the final output for this project. The performance of the model used for this API is available to see here.
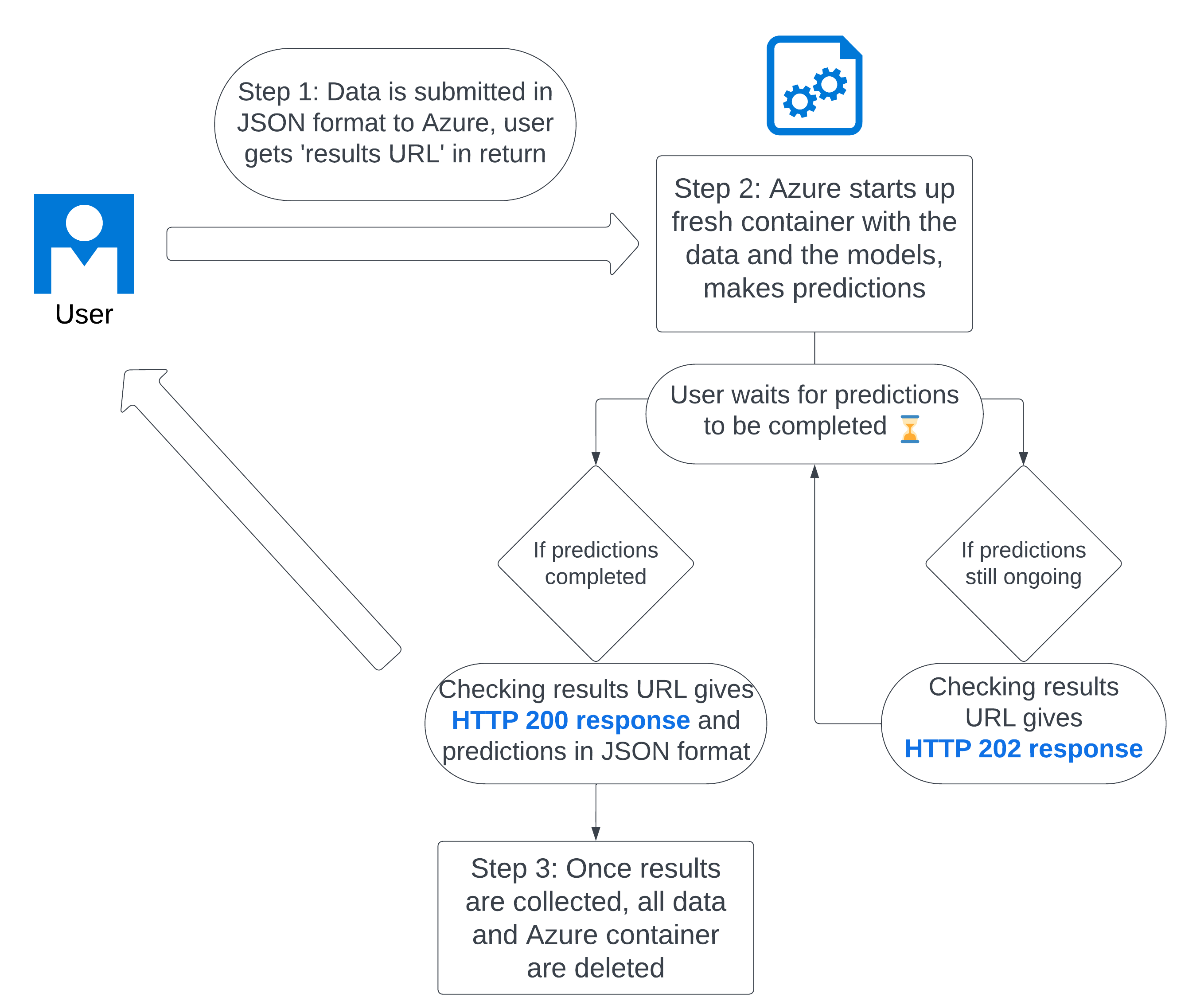
The Slow API (Best performance, but takes a long time)
This API is slow and slightly more complicated to use, but it utilises all of the models that we trained for this project and has the best performance. The performance of these models is available here. This model is slow because the transformer-based models take up a lot of computer resources, and can take a long time to run.
Option B: Running the code yourself
GitHub has a file size limit of 100MB. The smaller models that can be shared on GitHub have been shared there, so it is possible to download and run them on your own machine using the pxtextmining package.
The transformer-based Distilbert models are very large and could not be shared directly on GitHub. However, we have packaged them up in a Docker container which is available on Github Container Registry. This container is what is used in the Slow API. Full details on how to use this are available here.