Slow API
This API is slower but uses the best performing models. The transformer-based Distilbert model consumes a lot of hardware resource, and as such required a different approach.
For predicting the multilabel categories, the API endpoint ensembles together Support Vector Classifier, Gradient Boosted Decision Trees (XGBoost), and Distilbert models.
For predicting text sentiment , the API endpoint utilises a Distilbert model.
The API URL endpoint is available on request. You will need an API key, please contact the project team to obtain one. The key should be passed as a code param with your API request.
How to make an API call
1. Prepare the data in JSON format. In Python, this is a list containing as many dicts as there are comments to be predicted. Each dict has three compulsory keys:
comment_id: Unique ID associated with the comment, instrformat. Each Comment ID per API call must be unique.comment_text: Text to be classified, instrformat.question_type: The type of question asked to elicit the comment text. Questions are different from trust to trust, but they all fall into one of three categories:what_good: Any variation on the question "What was good about the service?", or "What did we do well?"could_improve: Any variation on the question "Please tell us about anything that we could have done better", or "How could we improve?"nonspecific: Any other type of nonspecific question, e.g. "Please can you tell us why you gave your answer?", or "What were you satisfied and/or dissatisfied with?".
# In Python
text_data = [
{ 'comment_id': '1', # The comment_id values in each dict must be unique.
'comment_text': 'This is the first comment. Nurse was great.',
'question_type': 'what_good' },
{ 'comment_id': '2',
'comment_text': 'This is the second comment. The ward was freezing.',
'question_type': 'could_improve' },
{ 'comment_id': '3',
'comment_text': '', # This comment is an empty string.
'question_type': 'nonspecific' }
]
# In R
library(jsonlite)
comment_id <- c("1", "2", "3")
comment_text <- c(
"This is the first comment. Nurse was great.",
"This is the second comment. The ward was freezing.",
""
)
question_type <- c("what_good", "could_improve", "nonspecific")
df <- data.frame(comment_id, comment_text, question_type)
text_data <- toJSON(df)
2. Send the JSON containing the text data in a POST request to the API. Ensure that you include your API key, which should be stored securely.
The model(s) used to make predictions can be selected with the target param. The options for this param are:
m: multilabels: sentimentms: both multilabel and sentiment.
# In Python
api_key = os.getenv('API_KEY')
params_dict = {'code': api_key, 'target': 'ms'}
url = os.getenv('API_URL')
response = requests.post(url, params= params_dict, json = text_data)
# In R
library(httr)
api_key <- Sys.getenv("API_KEY")
params_dict <- list(code = api_key, target = "ms")
url <- Sys.getenv("API_URL")
response <- POST(url, query = params_dict, body = text_data, encode = "json")
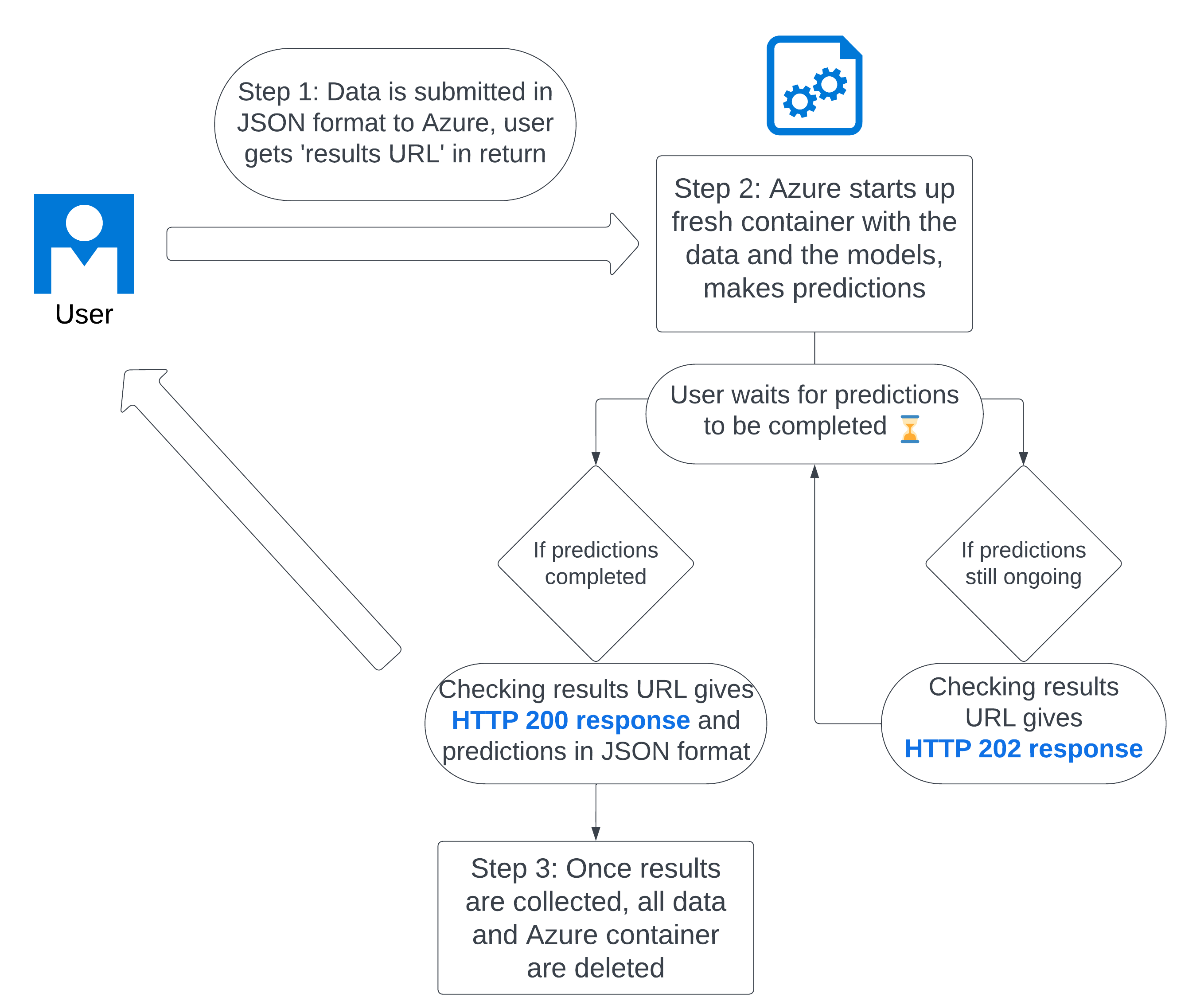
3. If the POST request is successful, you will receive a response with a 202 code, and a URL to retrieve your results, called the results URL. For example:
# In Python
if response.status_code == 202:
results_url = response.text
print(f"URL for results is {results_url}")
# In R
if (http_status(response) == 202) {
results_url <- content(response, as = "text")
}
print(results_url)
4. Use a GET request to check the results URL. If your predictions are not yet ready, you will receive a 202 response. If they are ready, you will receive a 200 response.
What is happening behind the scenes? The API has received your data and has started up a secure Azure container instance with your data stored in blob storage. The Docker container will install the pxtextmining package and make predictions using your data. Starting up a fresh container instance can take up to 5 minutes, and predictions using the slow transformer models can some time, up to 5 further minutes per 1000 comments. Once the predictions are complete, it will delete your data and save the predictions in blob storage.
Once you receive a 200 response, your results are available in JSON format. Please note that this will only be available once; once you have collected the data, it will be deleted due to security reasons and your results URL will no longer be valid.
You can set up a loop to check if your results are ready every 5 minutes, as follows.
# In Python
while True:
results_response = requests.get(results_url)
if results_response.status_code == 200:
final_labels = results_response.json()
break
else:
print('Not ready! Trying again in 300 seconds...')
time.sleep(300)
print('Predicted labels':)
print(final_labels)
# In R
while (TRUE) {
results_response <- GET(results_url)
if (results_response$status_code == 200) {
final_labels <- fromJSON(content(results_response, "text"))
break
} else {
cat("Not ready! Trying again in 300 seconds...\n")
Sys.sleep(300)
}
}
cat("Predicted labels:\n")
print(final_labels)