Text mining
What it can and can’t do, and what it could do
27 November 2024
Intro
- Range of possible applications
- There are a range of caveats depending on the use case
- Some of them are more relevant than others
- Some of them are “free”, and some aren’t
What is text mining?
- A variety of supervised and unsupervised methods
- The uses we’ll discuss today have no “understanding” of text (no “intelligence”)
- They all have the potential, therefore, to be very inaccurate (e.g. negation)
- But they can be a low cost way of gathering insight, properly applied
“I just want a bit of help sorting”
- This is one of the safer things to do
- There are a range of methods
- Some will give you some say of the “theme” of the piles, and some don’t
- Great for: sifting, looking at relative size of piles, novel suggestions for themes for text
- Bad for: accuracy, control over what’s in the piles
“I just want to find useful examples”
- Also quite a safe application, and one we implemented for patient experience
- The algorithm is just helping you to find things with a particular theme or sentiment
- You bring the understanding
- Many ways of achieving this, from easy to difficult
- Unsupervised and supervised
- Searching for strings vs semantic search
Generating summary statistics
- This needs to be done with care
- You can potentially lose a lot of nuance and meaning
- Even the best model is probably only around 80% accurate
- Useful for monitoring and making rough estimates about the size of things
- Not suitable for anything that needs accuracy (e.g. safeguarding)
“Free”
- Unsupervised learning is “free”- no labelling necessary
- Arguably you may as well use it for everything, speculatively
- However there are lots of models and parameters to set
- So “free” is not really “free”
What’s going on?
- Text models are only as sensible as their inputs
- We call the algorithm that turns text to numbers a “vectoriser”
Bag of words vs TF-IDF
- Bag of words just counts the number of times each word appears
- Crude but effective
- TF-IDF works similarly but makes rare words more important, which can help with topic modelling and classification
Word embeddings
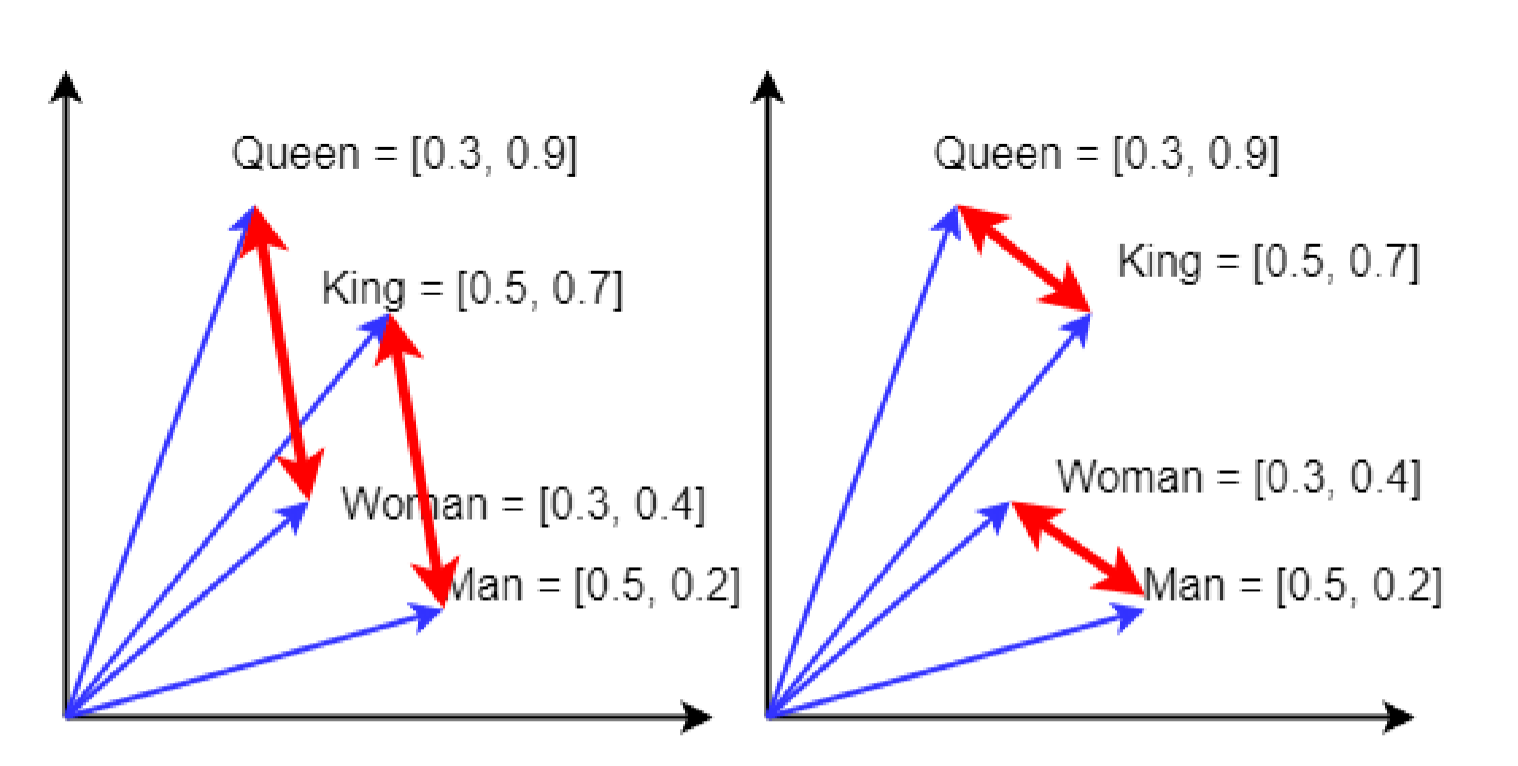
From Sutor et al., reproduced under fair use
Word embeddings cont.
- There are some smallish ones (like Glove), and some huge ones (like BERT)
- Vectors are the only way to encode meaning and context
The future
- A number of different things suggest themselves
- Use of topic models to explore and search
- Training of a supervised model for a particular project
The dream
- Zero shot model with human in the loop learning
Learn more about The Strategy Unit