Store Data Safely
Coffee & Coding
May 16, 2024
Avoid storing data on GitHub
Why?
Because:
- data may be sensitive
- GitHub was designed for source control of code
- GitHub has repository file-size limits
- it makes data independent from code
- it prevents repetition
Other approaches
To prevent data commits:
- use a .gitignore file (*.csv, etc)
- use Git hooks
- avoid ‘add all’ (
git add .) when staging - ensure thorough reviews of (small) pull-requests
What if I committed data?
‘It depends’, but if it’s sensitive:
- ‘undo’ the commit with git reset
- use a tool like BFG to expunge the file from Git history
- delete the repo and restart 🔥
A data security breach may have to be reported.
Data-hosting solutions
We’ll talk about two main options for The Strategy Unit:
- Posit Connect and the {pins} package
- Azure Data Storage
Which to use? It depends.
{pins} 📌
A platform by Posit
A package by Posit
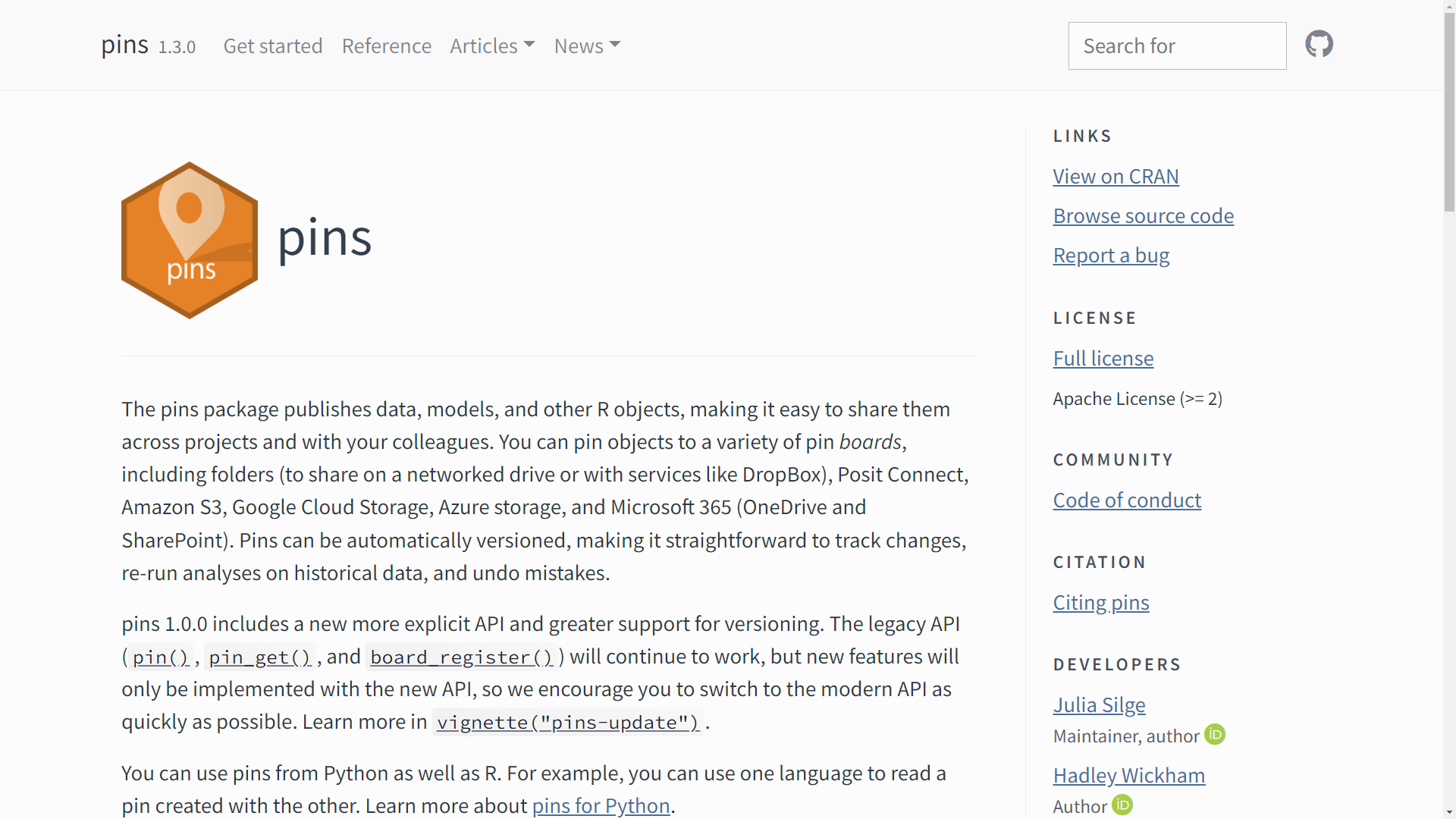
Basic approach
Live demo
- Link RStudio to Posit Connect (authenticate)
- Connect to the board
- Write a new pin
- Check pin status and details
- Pin versions
- Use pinned data
- Unpin your pin
Should I use it?
⚠️ {pins} is not great because:
- you should not upload sensitive data!
- there’s a file-size upload limit
- pin organisation is a bit awkward (no subfolders)
{pins} is helpful because:
- authentication is straightforward
- data can be versioned
- you can control permissions
- there are R and Python versions of the package
Azure Data Storage 🟦
What is Azure Data Storage?
Microsoft cloud storage for unstructured data or ‘blobs’ (Binary Large Objects): data objects in binary form that do not necessarily conform to any file format.
How is it different?
- No hierarchy – although you can make pseudo-‘folders’ with the blobnames.
- Authenticates with your Microsoft account.
Authenticating to Azure Data Storage
- You are all part of the “strategy-unit-analysts” group; this gives you read/write access to specific Azure storage containers.
- You can store sensitive information like the container ID in a local .Renviron or .env file that should be ignored by git.
- Using {AzureAuth}, {AzureStor} and your credentials, you can connect to the Azure storage container, upload files and download them, or read the files directly from storage!
Step 1: load your environment variables
Store sensitive info in an .Renviron file that’s kept out of your Git history! The info can then be loaded in your script.
.Renviron:
AZ_STORAGE_EP=https://STORAGEACCOUNT.blob.core.windows.net/Script:
Tip: reload .Renviron with readRenviron(".Renviron")
Step 1: load your environment variables
In the demo script we are providing, you will need these environment variables:
Step 2: Authenticate with Azure
The first time you do this, you will have link to authenticate in your browser and a code in your terminal to enter. Use the browser that works best with your @mlcsu.nhs.uk account!
Step 3: Connect to container
If you get 403 error, delete your token and re-authenticate, try a different browser/incognito, etc.
To clear Azure tokens: AzureAuth::clean_token_directory()
Interact with the container
It’s possible to interact with the container via your browser!
You can upload and download files using the Graphical User Interface (GUI), login with your @mlcsu.nhs.uk account: https://portal.azure.com/#home
Although it’s also cooler to interact via code… 😎
Interact with the container
Load csv files directly from Azure container
df_from_azure <- AzureStor::storage_read_csv(
container,
"newdir/cats.csv",
show_col_types = FALSE
)
# Load file directly from Azure container (by storing it in memory)
parquet_in_memory <- AzureStor::storage_download(
container, src = "newdir/cats.parquet", dest = NULL
)
parq_df <- arrow::read_parquet(parquet_in_memory)Interact with the container
What does this achieve?
- Data is not in the repository, it is instead stored in a secure location
- Code can be open – sensitive information like Azure container name stored as environment variables
- Large filesizes possible, other people can also access the same container.
- Naming conventions can help to keep blobs organised (these create pseudo-folders)
Learn more about Data Science at The Strategy Unit