Ensembling models
news
We found that there are three different model architectures / algorithms that produced a reasonable performance for predicting the themes: XGBoost, Distilbert, and Support Vector Machine. We decided to combine the three models together, in order to build upon their individual strengths and improve overall performance. In data science terminology, this is called “ensembling”.
We tried three different methods of ensembling:
- Taking all the predicted labels from each model. If Models A and B predicted the label “Safety & security” and Model C predicted the label “Feeling safe”, we would take both “Safety & security” and “Feeling safe” as the predicted labels for the text. This method resulted in a higher recall score but lower precision.
- Taking predicted labels only if at least two models predicted it. This is called “Hard voting” in data science terminology. If Models A and B predicted the label “Safety & security” and Model C predicted the label “Feeling safe”, we would take only “Safety & security” as the predicted label for the text. This is because “Feeling safe” was predicted by only one model. This method did not increase performance.
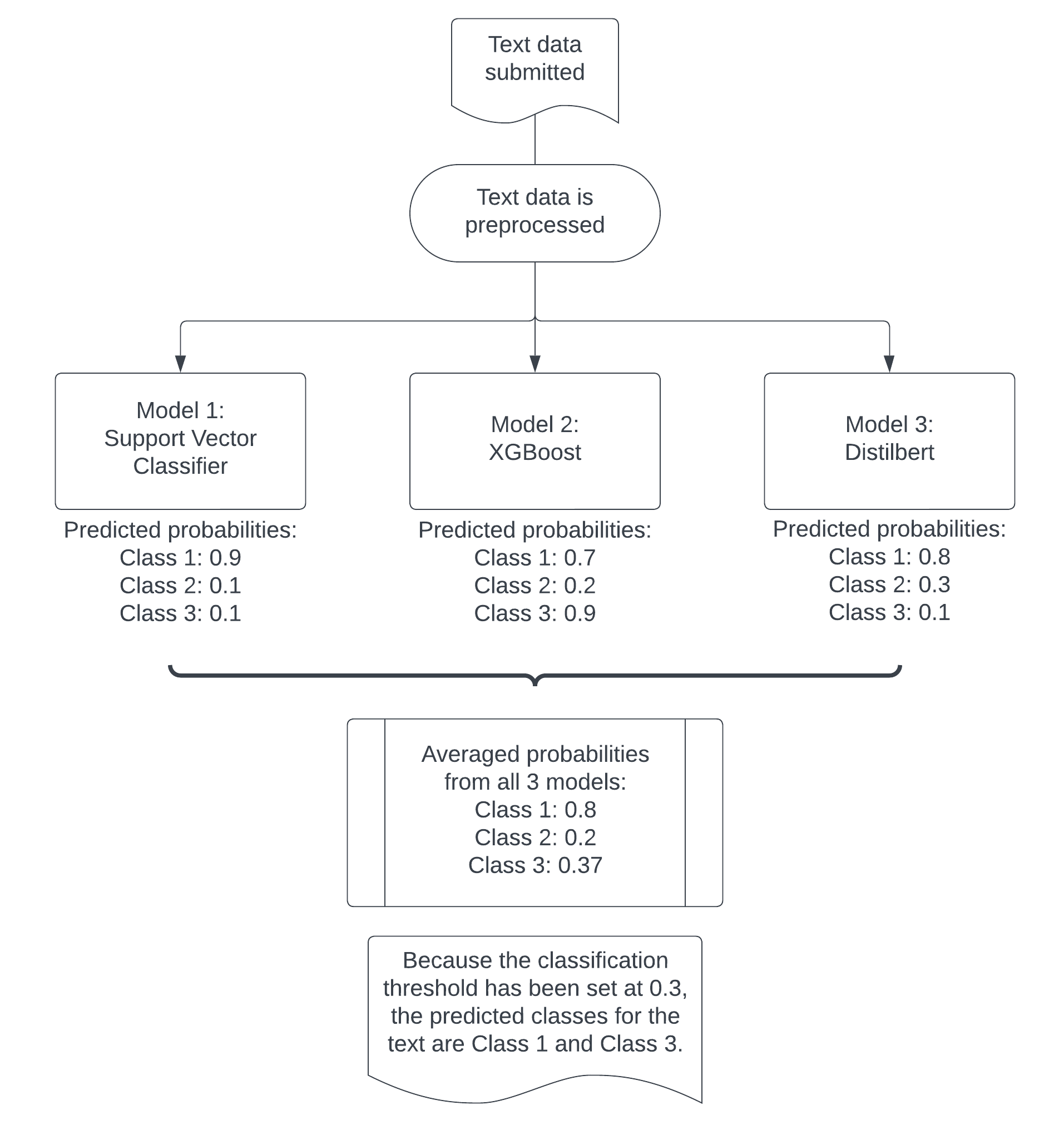
- Taking the predicted probabilities from each model and averaging them. This is called “Soft voting” in data science terminology. For example, if Models A, B, and C predicted the probability of the text belonging to the class “Feeling safe” as 0.2, 0.9 and 0.8 respectively, the average would be 0.63. This method worked the best, particularly when the threshold for accepting a predicted label was lowered to 0.3. This offered the best balance between precision and recall.
We have opted for method 3, as it offered the best balance between improving precision and recall. However, it also takes a longer time as we need to wait for all three models to make their predictions before we combine them. We are using this method with the slower “wait” API.