Productionising an LLM with limited hardware resources
For this project, we tried several different machine learning algorithms. The best performing algorithms were the Support Vector Classifier, Gradient Boosted Decision Trees (XGBoost), and Distilbert. For the multilabel categories, we found that these three models were largely comparable to one another but that they produced the best results when combined. The Distilbert model outperformed the others for predicting text sentiment (i.e., positive/negative/neutral).
The Distilbert model is a transformer-based model, which means that it is very slow and requires a lot of computation power. When we tried to deploy it on our RStudio Connect server, we found that it was consuming 100% of the server’s resources! This was not sustainable and we needed to find another way to make this model available.
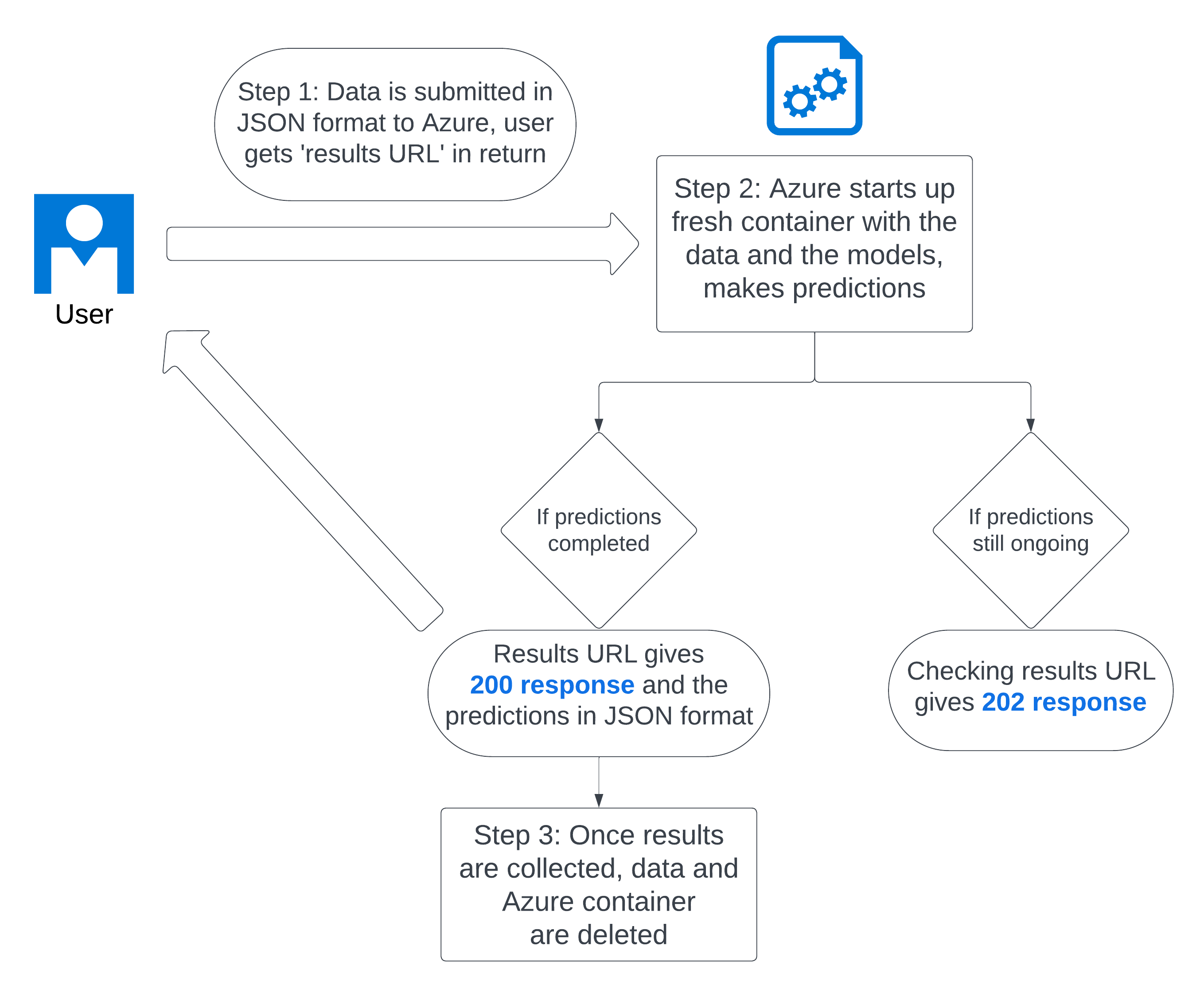
The solution that we have come up with is to use Azure Container Instances to host the model. Now, when users send their data for predictions, they get a unique results URL to check. A Docker container with their data is started up, which also installs the pxtextmining package and loads the models. This can take a few minutes, as a fresh instance is set up every time. The Docker container then makes the predictions based on the data, and saves the predictions (without the text). The process of making the predictions can be quite slow, approximately 10 minutes for 5,000 comments. After predictions are made, the original data is deleted, and the predicted categories are returned via the unique results URL. The container is then shut down completely.
We adopted this approach because it is more cost effective. We only pay for the length of time that the container instance is running - around 5-30 minutes, depending on the number of comments submitted. However, this does mean that it is a slower process overall as the container instance needs to be started up from scratch every time. It therefore makes more sense to use this for processing many comments at once. It’s also a slightly more complicated API to use, but we have provided guidance and example code to aid our end users.
We are still maintaining the API which uses the lightweight sklearn model. The performance of the model here is less good, but we think it’s important to maintain a ‘quick and easy’ solution as well as the more performant but much slower approach.
Do you have experience with deploying slow, resource-intensive models with limited resources? What were your solutions?